Whether typeset or handwritten, the input is processed to form a set of symbols, their positions, and sizes. For typeset input, working from scanned images of pages, there is a large variety of fonts, sizes and styles. Within a single publication this will be restricted to a smaller subset. Raw input pixels have to be segmented into individual symbols and then recognised. The analogous problem for online handwritten input is determining which strokes belong to which characters, then recognising them.
Some symbols do not have a constant aspect ratio, for example:
brackets, ![]() ,
and
,
and ![]() .
Their size depends on the symbols
that they are associated with. The segmentation process must also be
able to find symbols that are inside others. This allows for the
recognition of the square-root operator, ``
.
Their size depends on the symbols
that they are associated with. The segmentation process must also be
able to find symbols that are inside others. This allows for the
recognition of the square-root operator, ``![]() '' and any other
symbols inside it.
'' and any other
symbols inside it.
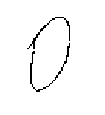
(a) 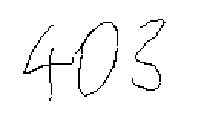
(b) 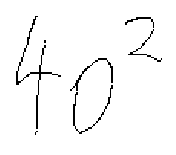
(c) |
Some systems
enable feedback to the character recogniser from later stages of
formula processing, so that the identity of symbols can be determined
based on surrounding symbols. This helps with cases like that
illustrated in Figure ![]() . The symbol shown in
Figure 2.2(a) could be either a o (the letter o) or a
0 (the digit zero). It is not until it is viewed in the context of
the surrounding symbols that its identity can be determined. In
Figure 2.2(b) it is a 0, in Figure 2.2(c) it
is an o.
. The symbol shown in
Figure 2.2(a) could be either a o (the letter o) or a
0 (the digit zero). It is not until it is viewed in the context of
the surrounding symbols that its identity can be determined. In
Figure 2.2(b) it is a 0, in Figure 2.2(c) it
is an o.
For handwritten input there is also a large variety of writing styles. It would be ideal to have a recogniser sufficiently flexible so that it would be possible to train it to work well with a particular user, but also have sufficient generality so that multiple users can use it without additional training.