Some symbols have many possible meanings and a distinction can only be made by examining it in the context of surrounding symbols. Examples of unambiguous symbols, and several ambiguous ones are listed here.
Some of the ambiguities listed above are concerned with understanding the underlying meaning of things: their semantics. Others are to do with syntax. For example, the last case is to do with semantics. Determining the meaning of Xa is impossible without the knowledge of what the author intended it to mean. The second example above, determining the number of limits on an integral, is a syntactical problem. If a limit is found, its function is unambiguous. The problem is that the number of limits to look for is indeterminable in advance.
A large amount of reliance is placed on the knowledge and experience of the person reading mathematical formulae. They are expected to understand the context in which something is written, and thus interpret things correctly. To build such experience into an automated system can be difficult.
If the purpose of parsing the formula is to produce LATEX that generates output that looks like the user's input, determining the underlying meaning is not as important; we are only interested in appearance, not meaning. If we are generating input for mathematical computation packages, such as Mathematica or Matlab, to do calculations with or operations on the formulae, then it is important to know the underlying meaning of conventions that the formula's author uses, so that a correct command string can be produced.
Anderson and Bernstein believe that syntax and semantics of a formula are different, and say that the parsing stage should only return something which describes the layout of the formula. Bernstein's view is that if we are intending to pass the formula onto some later stage that has its own input format, then the problem of going from the layout description to this input format should be done as a subsequent stage of processing. This could be done, for example, with a 1D string parser.
An example of a formula represented by a layout description follows. This is taken from the paper by Fateman, Tokuyasu, Berman and Mitchell .
The formula
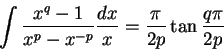
(hbox
(vbox integral nil nil)
(vbox quotient
(hbox (expbox x q) - 1)
(hbox (expbox x p) -
(expbox x (box - p))))
(vbox quotient
(hbox d x)
x)
=
(vbox quotient
pi
(hbox 2 p))
Tan
(vbox quotient
(hbox q pi)
(hbox 2 p)))
The hbox and vbox are operators that perform horizontal
and vertical concatenation of symbols and subexpressions, in a similar
manner to the concatenation operators that Martin
uses , described in Section ![]() . For
example, a fraction is a vertical concatenation of the numerator, a
horizontal line and the denominator.
. For
example, a fraction is a vertical concatenation of the numerator, a
horizontal line and the denominator.
Splitting the formula processor into two parts with the first stage being a layout processor returning a description of the layout of the formulae, and the second stage being a formula processor that takes the layout description and returns the command-string for the formula, has the advantages that:
It can also be argued that a single combined function unit can provide the same thing, if it uses a carefully chosen final language. For example, LISP-like notation essentially describes the layout of a formula. Splitting the process into two parts means you have to write a parser that will take the positional description and output a more human-readable version, such as LATEX or a Mathematica command string. It also makes it harder for the layout processor to use contextual information in making choices in ambiguous situations, as the layout processor is now a separate part.